Key Takeaways
- The FHIR® Bulk API provides a standardized way to extract and transfer large healthcare data sets, simplifying integration and enhancing interoperability.
- Using asynchronous processing, the FHIR® Bulk API enables efficient large-scale data transfers, reducing latency and boosting performance.
- The FHIR® Bulk API supports comprehensive data analysis for improved patient outcomes and ensures compliance with regulatory standards, such as the 21st Century Cures Act.
- The FHIR® Bulk API offers powerful capabilities, such as kick-off requests and type filtering, allowing tailored data extraction and efficient handling of large datasets.
The FHIR® Bulk API provides a powerful solution for healthcare data extraction and integration. While the healthcare industry generates about 30% of the global data, there’s a lack of ready access and easy exchange of said data. This creates a fundamental barrier in transforming healthcare into a data-driven enterprise. The Health Level Seven Fast Healthcare Interoperability Resources (HL7 FHIR®) standard aims to solve this issue. The OMOP and FHIR® standards are crucial in facilitating data standardization and interoperability to provide an easier way for data to be accessed, shared, and analyzed.
Since its first publication, FHIR® has become widely adopted, in part thanks to the 21st Century Cures Act (US), which requires healthcare entities to have an application programming interface (API), providing easy access to all data elements of a patient’s electronic health record. As a result, FHIR® is helping healthcare stakeholders solve the biggest challenges of health data interoperability and boost data-driven innovation.
One way FHIR® helps streamline health data exchange is with the FHIR® Bulk API, which allows you to extract large volumes of data to support various use cases across healthcare, research, and public health domains. Our team has implemented both Bulk FHIR® Export and Import within the Kodjin FHIR® Server.
In this article, we’ll take a closer look at the HL7 FHIR® Bulk Data API (or Flat FHIR® API), how it’s API for data extraction works, and why it makes such a difference. We’ve also put together a Bulk FHIR® API Postman collection featuring examples of how to export data in the Kodjin server. You can use this collection to test FHIR® bulk export functionality yourself.
What Is the FHIR® Bulk API?
The HL7 FHIR® Bulk API provides a convenient way to download standardized health datasets from EHRs on a large scale. It allows certified health information technology owners to enable authorized clients to request and extract population datasets from cloud-based FHIR® servers.
Unlike the regular FHIR® REST API, bulk data export makes retrieving data possible in a single request rather than hundreds. In addition, the export request can be configured to define which FHIR® data types should be exported and how to filter them.
So in short, to answer the question, what is FHIR® bulk data export? It’s a standardized method defined to facilitate the extraction of large datasets from EHRs via FHIR® servers.
To lower the load on system performance, the FHIR® Bulk Data API specification enables asynchronous request processing, which also leverages a system-to-system SMART backend services authentication and authorization framework for security.
Exported datasets are stored in files and can be downloaded by the client when ready. The amount of time it takes to process a request depends on the size of the dataset and the number of FHIR® resources. The data is in newline delimited JSON (NDJSON) format, which takes less space and is more convenient for large amounts of data than a regular searchset response.

How to Use the FHIR® Bulk API for Data Extraction and Integration
As previously mentioned, FHIR® Bulk follows an asynchronous request pattern for healthcare data extraction,meaning that once the export query has been sent, the server will indicate that the process has started. A client can check the status by polling from the Content-Location header returned by the server. The process is initiated by a kick-off request to one of the available export endpoints:
- …/Patient/$export—exports data on all patients (works with all resources in Patient Compartment)
- …/Group/[group id]/$export—export all data for patients in a specified group
- …/$export—full system-scale export of all datasets
The extraction results can be filtered using query parameters described in the picture below. In addition, servers can limit what data is retrieved to comply with specific policies or regulations.
Key FHIR® Bulk API query parameter

How to configure a kick-off request
Example of _typeFilter parameter use
A _typeFilter parameter can be used to filter resources that meet the specified criteria. The criteria is a search string with the same interpretation as if it was appended to the base URL and submitted to the FHIR® search using REST API.
Any valid search string can be used, including ones with modifiers and prefixes.
The example below demonstrates how to configure a kick-off request to export only patients from a group who had a reaction to immunization. In this case, _typeFilter contains a search immunization query with :missing=false modifier.
Example Request:
curl --location --request GET 'https://kodjin-staging.edenlab.dev//fhir/Group/0a60d2a2-38ce-49f6-ac45-42347193af50/$export?_type=Immunization&_typeFilter=Immunization%3Freaction-date:missing%3Dfalse' \
--header 'content-type: application/json' \
--header 'prefer: respond-async' \
--data-raw ''Example of POST request use
Some requests may contain lots of filter parameters. In this case, it is convenient to use a POST request and supply filter parameters in the FHIR® Parameters Resource in the body. The example below demonstrates how to export resources filtered by practitioner ID. The request contains the _typeFilter parameter for each resource type.
Example Request:
curl --location --request POST 'https://kodjin-staging.edenlab.dev//fhir/$export' \
--header 'content-type: application/json' \
--header 'prefer: respond-async' \
--data-raw '{"resourceType" : "Parameters",
"parameter" : [
{"name":"_since",
"valueInstant": "2022-01-01T00:00:00Z"},
{"name":"_type",
"valueString": "Observation, Condition, Procedure, Immunization"},
{"name":"_typeFilter",
"valueString": "Observation?performer=Practitioner/9bac339d-ac3b-4715-bf9a-1dab1dec7fa2"},
{"name":"_typeFilter",
"valueString": "Condition?asserter=Practitioner/9bac339d-ac3b-4715-bf9a-1dab1dec7fa2"},
{"name":"_typeFilter",
"valueString": "Procedure?performer=Practitioner/9bac339d-ac3b-4715-bf9a-1dab1dec7fa2"},
{"name":"_typeFilter",
"valueString": "Immunization?performer=Practitioner/9bac339d-ac3b-4715-bf9a-1dab1dec7fa2"}
]
}'Example of _elements parameter use
In some cases, you will need only a short set of fields for analysis instead of the entire resource. The example below demonstrates how to export only condition and observation codes using an _elements parameter.
Example Request:
curl --location --request GET 'https://kodjin-staging.edenlab.dev//fhir/$export?_type=Observation,Condition&_since=2022-07-13T00:00:00Z&_elements=code' \
--header 'content-type: application/json' \
--header 'prefer: respond-async' \
--data-raw ''If the request were successful, the server would return an HTTP header with a content location, which you can check to see the request’s status. Once the extraction is finished, the completion response will contain a JSON manifest with the locations of the extracted data in files in the NDJSON format (some servers support the use of other formats as well). Each file contains one type of FHIR® resource.
The final step is to send a ‘GET’ file request to download the bulk data. The complete data extraction in the healthcare process is illustrated below.
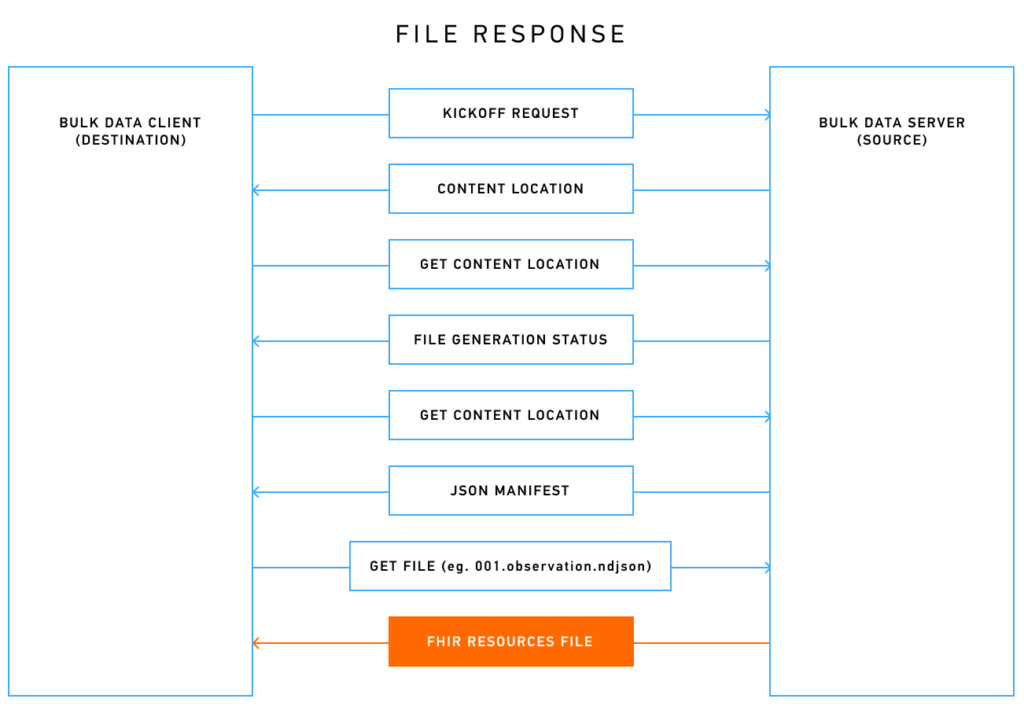
Security is paramount to the sensitive nature of healthcare data.
Therefore, the FHIR® specification recommends implementing a SMART backend services authorization to secure bulk data requests.
This authorization framework leverages short-lived access tokens to verify requests.
Here’s how it works:
- A user generates a token signed with its private key and a client ID to send a request.
- The FHIR® server validates the request using the user’s public key.
- If successful, the server issues a temporary access token that’s used to send data extraction requests.
Once the token expires, the process needs to be repeated. This also allows user access control, as servers can be configured to restrict data access associated with a particular client ID.
Read also: RBAC vs. ABAC Approach in FHIR® Projects
Benefits of Using the FHIR® Bulk API for Healthcare Interoperability
FHIR® Bulk API provides a standardized, efficient, scalable, and secure way for healthcare organizations to exchange large amounts of data, which can help to improve patient care and streamline healthcare operations. Below we will take a look at some of the benefits of using the FHIR® Bulk API for healthcare interoperability:
Standardization
The FHIR® Bulk API provides a standardized method for exchanging large volumes of healthcare data, enabling healthcare organizations to easily extract, transfer, and receive data using a common format and protocol. This standardization ensures interoperability between different systems and reduces the complexity associated with integrating disparate data sources. By adhering to a unified standard, healthcare providers can streamline data exchange processes, ensuring consistent data quality and facilitating smoother communication across various platforms and stakeholders.
Efficiency
The FHIR® Bulk API allows healthcare organizations to extract and analyze large volumes of data to identify trends and patterns in population health, conduct clinical studies, and generate quality reports required for regulatory compliance and performance monitoring. By enabling comprehensive data analysis, healthcare providers can gain deeper insights into patient populations, tailor treatment plans, and implement preventative measures. This proactive approach leads to improved patient outcomes, reduced healthcare costs, and enhanced overall care quality. Additionally, large-scale data analysis can support precision medicine initiatives, ensuring that treatments are customized to individual patient needs.
Improved Patient Care
The FHIR® Bulk API enables healthcare organizations to extract and analyze large volumes of data to identify trends and patterns in population health, conduct clinical studies, and generate quality reports required for regulatory compliance and performance monitoring. This can help healthcare providers improve patient outcomes and reduce healthcare costs.
Cost Management
Previously APIs for bulk data transfer required a multi-step process which resulted in high costs of integration projects. The FHIR® Bulk API significantly simplifies the data extraction process which can help healthcare organizations reduce costs and make the process of transforming bulk data for analytics more efficient.
Previously, APIs for bulk data transfer required a multi-step process, resulting in high costs for integration projects. The FHIR® Bulk API significantly simplifies the data extraction process, helping healthcare organizations reduce costs and make the transformation of bulk data for analytics more efficient. By eliminating redundant steps and leveraging automated data extraction methods, the FHIR® Bulk API minimizes the need for extensive manual intervention and reduces the associated labor costs. This cost-effective approach enables healthcare organizations to efficiently prepare data for data analytics.
Better performance
By using an asynchronous approach, the FHIR® Bulk API addresses the issue of FHIR® APIs needing hundreds and thousands of serial requests to download large volumes of data. This asynchronous method allows data to be processed and transferred in parallel, significantly enhancing performance and reducing latency. Consequently, healthcare organizations can handle large-scale data transfers more efficiently, ensuring timely access to essential information and supporting real-time decision-making processes. This improved performance is particularly beneficial for large healthcare networks and research institutions that require rapid data processing capabilities.
Regulatory Compliance
The FHIR® Bulk API facilitates regulation for more standardized ways of transmitting all health data and reporting. It has already become a requirement for one of the criteria of the ONC certification for Standardized API for patient and population services. By complying with these regulatory standards, healthcare organizations can ensure that they meet legal requirements and maintain the highest levels of data security and privacy. This compliance not only helps avoid potential legal issues but also builds trust with patients and stakeholders, reinforcing the organization’s commitment to data integrity and patient confidentiality.
What are some use cases for the FHIR® Bulk API?
The FHIR® Bulk API promises to become invaluable for healthcare interoperability by providing a simple, standardized way of extracting and importing large volumes of data. By leveraging the FHIR® Bulk API, healthcare providers and organizations can easily manage and access patient data while improving outcomes and reducing costs. Let’s take a closer look at some of the specific use cases of the FHIR® Bulk API in healthcare.
Population health management
Healthcare organizations can use the FHIR® Bulk API to extract patient data from their EHR systems and analyze it to identify trends and patterns in population health. This can help them develop targeted interventions and improve patient outcomes.
Clinical research
Researchers can use the FHIR® Bulk API to extract data from multiple EHR systems to conduct clinical studies and analyze patient outcomes. This can help them gain insights into the effectiveness of different treatments and interventions.
Public health reporting
The FHIR® Bulk API can facilitate public health reporting by allowing healthcare organizations to extract and analyze patient data to identify public health trends and outbreaks. This can aid in the development of targeted interventions to improve population health outcomes.
Patient data access
Patients can use the FHIR® Bulk API to extract their health data from different EHR systems and aggregate it in a personal health record (PHR), allowing them to better manage their health and share their data with healthcare providers as needed.
Data analytics
Healthcare organizations often need to consolidate data from various sources into centralized data warehouses for advanced analytics and business intelligence purposes. The FHIR® Bulk API facilitates the efficient transfer of large datasets, enabling robust data warehousing solutions and enhancing analytical capabilities.
Takeaway
In the US, to comply with the 21st Century Act and its requirements to provide easy clinical data access, the adoption of the FHIR® Bulk Data API (or as it’s called Flat FHIR® API) is expected to become even more widespread across the healthcare ecosystem.
Additionally, there is substantial community interest in implementing a bulk-import FHIR® data ($import) operation. There are currently two proposals published by the SMART on FHIR® team that are still in their prototyping phase. You can test them out and provide feedback to help accelerate the development.
We hope you’ve found this article useful. For more practical examples of how to export data with Bulk FHIR® API, please refer to our Postman collection.
If you want to implement FHIR® in your system, need help transferring or extracting FHIR® data, or want to integrate your system with an EHR, our team can help. We specialize in delivering scalable healthcare data analytics solutions that leverage FHIR® standards to ensure seamless data interoperability, efficient data management, and actionable insights for healthcare organizations. Contact us to discuss your project!
FAQ
How does the FHIR® Bulk API work?
The FHIR® Bulk API uses a set of endpoints and parameters to extract and integrate healthcare data in bulk. It supports different data formats and allows for customization based on specific use cases.
Who can benefit from using the FHIR® Bulk API for data extraction?
Healthcare organizations, health IT companies, and other stakeholders in the healthcare industry can benefit from using the FHIR® Bulk API for healthcare data extraction and integration.
What are the challenges of using the FHIR® Bulk API?
These challenges include data quality issues, privacy and security concerns, and technical complexities related to implementation and customization.