Duplicate medical records in healthcare can result in treatment errors, delays, and reduced administrative efficiency. For example, suppose a patient has two separate medical records in the same system, which complicates the access to their entire medical history for a doctor. In this case, healthcare professionals may miss important factors to consider when prescribing medicines, such as allergies, which can lead to incorrect treatment decisions and delays that cannot be tolerated, especially during emergencies. So how to prevent duplicate medical records?
In this article, you will explore the FHIR® MPI, ways to prevent duplicate medical records and discover how our approach helps reduce duplicate medical records in the healthcare industry.
What is MPI in Healthcare?
Are you wondering what is MPI in healthcare? Master Patient Index (MPI) is a service that solves problems with duplicate medical records in healthcare. The MPI service is described in the FHIR® standard, which the not-for-profit HL7 organization designed to standardize healthcare data exchange and ensure semantic interoperability in healthcare. However, sometimes the deduplication mechanisms of FHIR® MPI can be insufficient and require additional tailoring to cover the specific needs of a healthcare project.
How to Prevent Duplicate Medical Records According to FHIR®: MPI in the FHIR® Specification
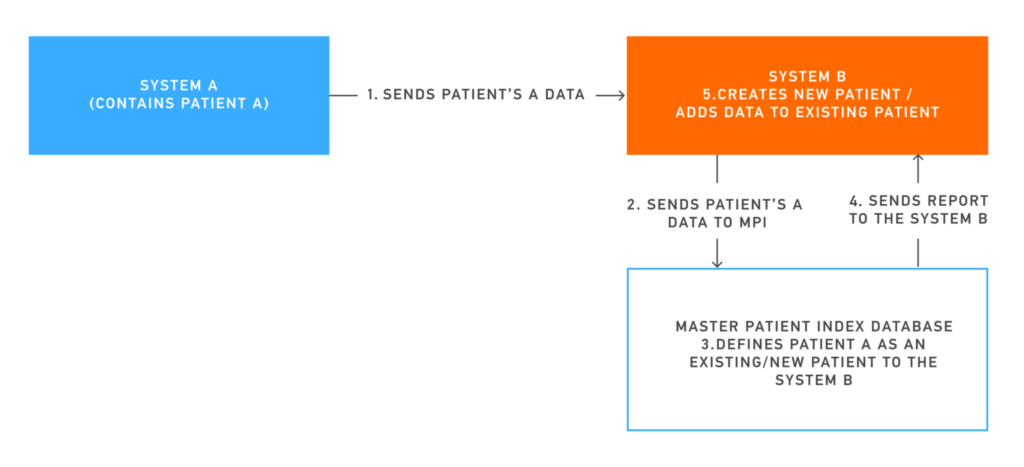
The FHIR® specification describes MPI as a service used to manage patient identification in a context where multiple patient databases exist. It also refers to MPI as the Operation $match on Patient resource since the FHIR® offers a “$match” operation that allows clients to request a patient match.
How does Operation $match on Patient work?
The “$match” operation is interpreted as input for the MPI algorithm to determine suitable matches from the patient set. The patient resource submitted to the operation only needs to be a valid instance and does not have to be complete or pass validation.
The matching algorithm and specific input requirements may vary among implementations, and the MPI may return inactive patients depending on the particular algorithm. The MPI returns a bundle of patient records ordered by the likelihood of a match, along with search scores and additional information indicating the quality of the matches.
The process generally includes incorporating current information, eliminating incorrect data, and merging duplicate medical records into comprehensive data about the patient.
Why is the Operation $match on the Patient’s resource insufficient for medical records deduplication?
The Operation $match on Patient provided by FHIR® is a helpful tool for identifying potential duplicates. However, it doesn’t specify the deduplication process itself. Hence, stakeholders should consider cooperation with industry experts like the team at Edenlab for building a custom MPI.
Even though duplication is among the most common problems with medical records, finding an out-of-the-box solution that will work for any healthcare project is impossible. Different healthcare systems may have varying requirements for matching patients, and a custom MPI should be tailored to the specific needs of any organization or healthcare system.
The Story Behind the Custom FHIR® MPI by Edenlab
What were the prerequisites for the creation of MPI?
The project’s main goal was to create a registry of medication prescriptions, maintain control over prescription issuance, and prevent abuse or accidental deviation from prescribed norms by controlling maximum doses of drugs. However, the reliance on an abstract patient dataset alone appeared insufficient, prompting the need for a centralized module to consolidate data in one central location.
The solution was creating a custom MPI component with the support of such processes as:
- Creating an account
- Applying changes to data in the account
- Search
- Deduplication.
Moreover, to ensure the authentication of specific events like prescription dispensing, an OTP (One-Time Password) was necessary. This OTP was sent to the phone number stored in MPI.
What were the tasks?
- Addressing the issue of duplicate medical records
- Consolidating flows between medical and insurance organizations
- Automating the registry of medication prescriptions and controlling the issuance of prescriptions
- Preventing abuse or accidental deviations from prescribed norms by controlling maximum doses.
The MPI: Functionality
The role of a FHIR® server in MPI
The Kodjin FHIR® Server was pivotal as the storage system for all medical data. While there was no separate dedicated component, Kodjin served as a repository. Moreover, the team has developed specific services outside the Kodjin framework to implement processes relevant to the MPI. Critical data, such as medication and medication prescriptions, reside within the Kodjin server.
Also, the future expected integration of the MPI with government registries allows for a more streamlined and efficient system, ensuring better data consolidation and validation.
Data Validation
Data validation is a crucial process in ensuring the accuracy and integrity of information. By integrating the MPI with relevant registries, data validation can be efficiently carried out. This integration allows for accessing external registries and cross-referencing data asynchronously, which enhances the deduplication and quality improvement.
Additionally, the MPI incorporates various fraud prevention rules, such as checking for excessive phone numbers linked to a patient or limiting the number of individuals listed as confidants. These synchronous checks play a vital role in preventing fraudulent activities and maintaining data integrity.
Data Model
The data model used in the MPI is derived from the standard FHIR® data model and customized to meet the specific requirements of the FHIR® MPI project. As the standard model had limitations, the team created extensions to incorporate additional attributes and accommodate unique business needs.
Standard FHIR® extensions were used to leverage the full potential of the FHIR® patient data model. Also, the development of the MPI involved mapping business requirements to the FHIR® attributes.
The team identified gaps between the desired business profile of a patient and the existing FHIR® attributes, added additional attributes using extensions, and marked unnecessary attributes as unused. Mapping healthcare data to HL7 FHIR® resources ensured the MPI accurately reflected the stakeholders’ expectations and met the project’s objectives.
Сontextualizing the MPI in the FHIR® Way
What way is the FHIR® way?
The FHIR® specification encompasses profiled resources and a specific manifest outlining the structure of resources and services. It extends the traditional REST architecture by introducing operations beyond basic resource manipulation methods like POST, PUT, PATCH, and DELETE. The Operation Framework allows for not only using extended operations like $everything, $validate, and $translate but also defining custom operations. This approach can introduce new features in the FHIR®-based servers while still keeping it the FHIR® way, a.k.a conformant to the specification.
Since FHIR® operates on resources without considering the context of the business process and the Kodjin FHIR® server serves only as a resource storage with a set of APIs, the custom operations built on the operation framework can be a solution for the complex business processes within healthcare organizations.
The custom operations developed for MPI service covered such processes as a secure update of the patient medical record by multiple sources, changing patients’ data with and without OTP verification, managing the life cycle of scanned copies of documents, etc. Below we will break down some of these cases.
Enabling controlled modifications with custom MPI operations
Example 1
Specific data points like religion can be modified without requiring patient confirmation. For instance, if Clinic A enters “Christian” as the patient’s religion and Clinic B later enters “Muslim,” such a modification is permissible. However, critical data elements, like the patient’s last name, require patient confirmation before any changes can be made.
Example 2
Suppose a patient visits a clinic, and the clinic needs to search for their existing record in the MPI to continue working with a patient. The clinic finds the patient but discovers a difference in the last name and decides to correct it.
In both cases, the clinic initiates a specific operation for updating a patient’s medical record, providing changes exclusively for the relevant parameters. As a result of this operation, a One-Time Password (OTP) is generated and sent to the patient as a confirmation mechanism. The changes are applied to the MPI only when the initiating clinic confirms the changes using the OTP. Without confirmation, the modifications remain unapplied, ensuring data integrity and preventing unauthorized alterations.
By creating this custom operation, we achieved controlled changes to be made to patient data based on the specific business process and with predefined data segments.
Customizing a FHIR® server by creating a business layer
The patient resource within the MPI is extensive, encompassing various data modification and maintenance process categories. Some data elements require confirmation for modification, while others can be changed without confirmation. For instance, adding a confidant person to the MPI requires applying the scanned documents for validation.
Managing data requires the implementation of a certain business logic, which the Kodjn Server itself does not have. So, the team created a business layer in an FHIR® way to provide a single interface and abstract the client from the server while dealing with a patient resource.
This abstraction ensures compatibility with diverse client requirements. The FHIR® interface, thus, serves as a standardized gateway for clients, enabling seamless integration and efficient data management.
Benefits of Implementing Custom MPI Operations in a FHIR® Way
Tailored Operations for Client Requirements
Implementing custom MPI operations within the FHIR® MPI allows healthcare organizations to customize operations according to client needs. This flexibility ensures the system can adapt to diverse business processes.
Simplified Management of Confidant Persons
By enforcing rules such as mandatory assignments based on age or submitting specific supporting documents, organizations can ensure the secure addition of trusted individuals. This process seamlessly adds, modifies, and uploads supporting documents in dedicated media storage.
Streamlined Data Modification with Change Requests
Instead of directly modifying patient data, healthcare clinics can submit requests for changes or patient registrations. This streamlined approach automates the application of data without requiring patient confirmation, resulting in a smoother workflow. In addition, organizations can enhance efficiency and ensure accurate and up-to-date patient information by maintaining data integrity throughout the modification process.
Comprehensive Document Versioning
With Kodjin, each change request is assigned a version, facilitating comprehensive tracking and auditing of modifications. This versioning mechanism ensures that all requests leading to the current state of the data are recorded in the Parameters resource. The ability to review and analyze changes enhances data transparency and accountability.
Challenges in Implementing FHIR® MPI
Here are the main challenges that hinder the implementation of FHIR® MPI in healthcare:
- Customization Needs: Healthcare systems have unique requirements for patient matching. Tailoring the MPI to align with specific organizational needs can be complex and time-consuming.
- Data Quality: Implementing FHIR® MPI may require extensive data validation and cleansing to eliminate errors and inconsistencies.
- Privacy and Security: FHIR® MPI implementations must adhere to strict data privacy standards to protect sensitive patient information.
The advantages of advancing patient care and streamlining healthcare operations highlight the significance of addressing these challenges. By tailoring solutions to meet specific organizational requirements, diligently validating data, and upholding stringent privacy and security standards, we can enhance healthcare data management and tackle the issue of duplicate medical records.
Reduce the Impact of Duplicate Medical Records in Healthcare with Edenlab
Thus, creating a custom MPI should be considered to make the “$match” FHIR® operation more advantageous for medical records deduplication. The team of certified FHIR® experts at Edenlab developed custom operations within the FHIR® paradigm to address this issue and provide our clients with one of the best ways to prevent duplicate medical records.
Our project is designed with a clear purpose: to prevent unauthorized data changes and reduce the impact of duplicate medical records while ensuring a seamless workflow. Through our innovative approach, we utilize requests to track and manage changes, allowing you to apply modifications when necessary.
With multi-step processes in place, we prioritize patient confirmation to safeguard against potential data discrepancies during the healthcare medical records deduplication process. We focus on protecting your valuable data and ensuring regulatory compliance in healthcare.
By collaborating with Edenlab, you gain access to a range of benefits that go beyond traditional match operations for deduplication. Our customized operations can be tailored to meet your specific requirements, allowing for a more precise and efficient data management process while revolutionizing medical record deduplication.
FAQ
- Are there any specific technical requirements for implementing FHIR® MPI?
Implementing FHIR® MPI necessitates adherence to the FHIR® standard, accurate data validation, seamless integration with other healthcare IT systems like EHRs, and robust privacy and security measures for patient data protection and regulatory compliance.
- How does FHIR® MPI handle patient data privacy and security?
By using solutions that comply with strict data privacy regulations, like HIPAA, a FHIR® MPI can handle patient data privacy and security.
- Can FHIR® MPI be integrated into existing healthcare IT systems, such as Electronic Health Records (EHRs)?
Integrating an FHIR® MPI with existing health IT systems demands proper data mapping and robust data exchange protocols.