As the digital age transforms various industries, healthcare stands out as a sector significantly influenced by technological advancements. With this transformation comes an avalanche of data, often sensitive and complex. Synthetic health data for analytics and synthetic healthcare data are game-changing innovations that address many of these data-associated challenges head-on.
What Is Synthetic Data?
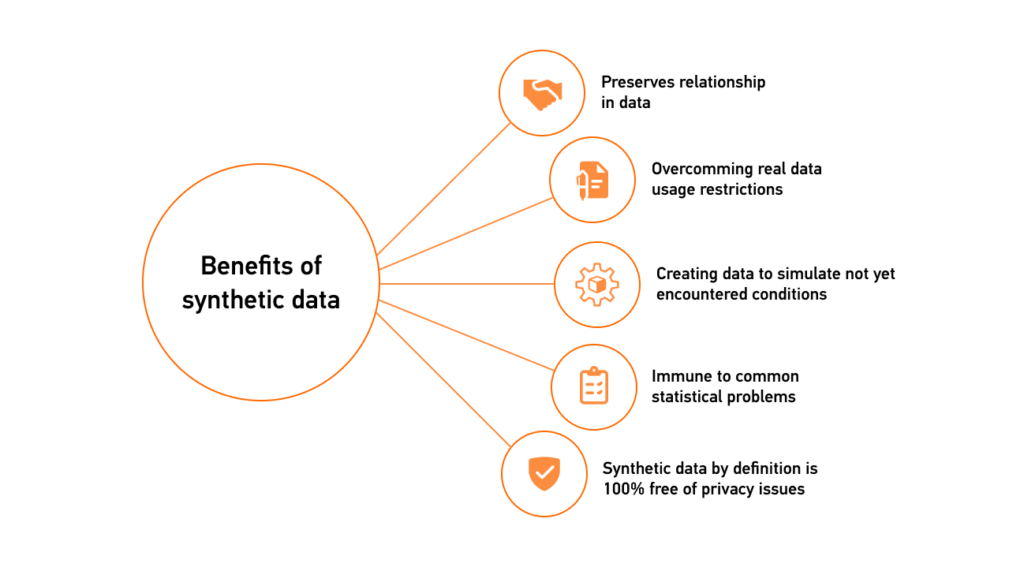
Synthetic data for healthcare refers to artificially generated data that closely resemble real-world healthcare data but do not contain actual patient information. These datasets are designed to mimic the structure, type, and format of real-world healthcare data, such as Electronic Health Records (EHRs), without compromising the privacy and confidentiality of individual records. The generated data aims to preserve the same relationships, patterns, and characteristics as the original dataset, making it a valuable resource for various applications, including analytics, research, and software development.
Synthetic healthcare data is generally produced using advanced statistical and machine learning models. These models are trained on original healthcare data to understand its structure, patterns, and variabilities. Once the model is adequately trained, it can generate new data that statistically resembles the original dataset but doesn’t contain any real patient information. For insights into how actual patient data is utilized to empower healthcare decisions, explore our article on real-world data for health research.
The quality of synthetic data depends highly on the model used for its generation. Different techniques may be employed, such as Generative Adversarial Networks (GANs), which consist of two neural networks—the generator and the discriminator—that work against each other to produce realistic synthetic data. Another approach could be using Bayesian networks to understand the probabilistic relationships between variables in the original dataset and generate synthetic data accordingly.
Because the data is synthetic, it reduces the risk of data leakage and protects individual privacy. It allows for wider and faster distribution of the data for research and other purposes due to minimal disclosure risks. Moreover, synthetic data can provide a more practical and cost-effective solution for software developers to test their applications with realistic but unreal patient data.
The Advantages of Synthetic Healthcare Data
Preserving Data Privacy
A principal merit of using synthetic health data for analytics is its potential to protect individual privacy. Data privacy has long been a serious concern in the healthcare industry. With synthetic healthcare data, however, individual identifiers are effectively removed, ensuring that datasets can be safely shared and analyzed without risking confidentiality.
Enhanced Data Availability and Accessibility
Another advantage is the greater accessibility and availability of data for researchers and healthcare professionals. Obtaining permission to use real-world healthcare data can be cumbersome, often limited by bureaucratic constraints. Synthetic data for healthcare offers an efficient alternative, enabling more extensive and less restricted access to data for research and analysis.
Accelerating Research and Development
The COVID-19 pandemic highlighted the need for quick and easy access to healthcare data for research purposes. Synthetic healthcare data, because of its accessibility, allows researchers and healthcare professionals to bypass the time-consuming process of data acquisition, thereby expediting their studies or clinical trials. This has been exemplified by the National Institutes of Health’s National COVID Cohort Collaborative (N3C), which employed synthetic data in healthcare to facilitate research and insights into COVID-19.
Use Cases and Applications

Synthetic data in healthcare can be leveraged in multiple ways, each with its unique benefits.
Protecting Privacy
A pressing concern in healthcare data management is the preservation of individual privacy. Synthetic health data mitigates this challenge effectively by creating a database where each entry is a statistical representation rather than a real patient’s information. This makes it incredibly difficult to re-identify records, providing an added layer of security. Organizations can use this to share de-identified datasets with minimal risk while complying with regulations like HIPAA or GDPR.
Improving Data Accessibility for Researchers
Another challenge in healthcare is limited data accessibility, mainly due to privacy concerns. Synthetic healthcare data provides a workaround by allowing datasets to be shared more liberally. With fewer worries about breaching privacy norms, these synthetic datasets can be distributed faster and to a wider audience, including academic researchers, healthcare organizations, and policymakers. This allows for more eyes on the data, encouraging diverse perspectives and innovative solutions to healthcare challenges.
Software Development and Testing
From the development perspective, synthetic data for healthcare serves as an invaluable resource for testing new software solutions and databases. Traditional testing methods often require sanitized real-world data, which is time-consuming to prepare and carries some risk. Synthetic data for healthcare, on the other hand, allows developers to generate test data that align closely with real-world scenarios without compromising patient privacy. This expedites the software development lifecycle and increases the robustness of the resulting software products.
Research on Stigmatized Diseases and Conditions
Certain medical conditions, such as opioid use disorder (OUD) or HIV, come with societal stigma that creates additional barriers to data collection and sharing. Here, synthetic data in healthcare emerges as a potent tool. By generating synthetic longitudinal records of those diagnosed with such conditions, researchers can gain insights into disease patterns, risk factors, and the effectiveness of various treatment programs. This is invaluable for designing targeted interventions without the ethical dilemmas commonly associated with using real patient data.
Emerging Health Challenges and Pandemics
The COVID-19 pandemic highlighted the urgent need for rapid, widespread data sharing to address emergent public health crises. The National COVID Cohort Collaborative (N3C) initiative, for instance, leveraged synthetic data in healthcare to quickly disseminate information to the broader research community. This allows for an accelerated research pace and enables citizen scientists to contribute to the data analysis and solution development processes.
It’s evident how synthetic data is not merely a stopgap or ‘second-best’ option but is increasingly becoming a frontline solution to overcome the data-related challenges in healthcare. It offers an avenue for accelerating research, enabling robust software development, and, most importantly, improving patient outcomes while preserving privacy.
Challenges and Limitations
Data Leakage and Privacy Concerns
Data leakage remains one of the most significant barriers to the widespread adoption of synthetic health data for analytics. While synthetic data aims to protect patient privacy by creating a dataset of artificial records, there’s still a risk of some original data attributes being exposed. This is particularly true when the synthetic dataset includes outliers or unique data points, which can be easily linked back to the original dataset.
Techniques like differential privacy can offer some level of protection against data leakage. However, the challenge persists, especially when the model used to generate the synthetic data is also accessible. In such cases, adversaries can employ inversion attacks to link synthetic records back to real patient data. This concern is even more pressing given the sensitivity of healthcare information, where the stakes are much higher with legal repercussions and patient trust.
Data Fidelity
The quality of synthetic healthcare data is another significant challenge. Synthetic data must accurately represent the original data’s statistical properties to be useful for analytics or machine learning models. However, synthetic data often falls short of capturing the underlying patterns and relationships among variables, which can limit its analytical value.
For example, the synthesizing process might lead to a reduction in the interdependence and co-variation among variables. In such cases, the synthetic data becomes less useful for analytics, as the relationships that exist in the real-world data are not adequately represented. This can be problematic in healthcare analytics, where understanding the complex interplay between different variables, such as symptoms, diagnoses, and treatments, is crucial for actionable insights.
Lack of Standardization
While synthetic data for healthcare offers many advantages, there’s still no widely accepted benchmark or validation framework to ensure that synthetic datasets are comparable to real-world data in quality and utility. This makes it challenging for healthcare organizations to assess the viability of synthetic data for specific use cases or stages of research. With no industry-wide standards, organizations might hesitate to invest time and resources in synthetic data generation and utilization.
This lack of standardization affects the validation process and also hampers the broader adoption of synthetic data in healthcare. Without benchmarks, it’s difficult to assure clinicians, researchers, and policymakers that synthetic data can provide reliable insights, affecting the rate at which synthetic data is integrated into healthcare analytics pipelines.
Addressing these challenges is essential for the sustainable growth and adoption of synthetic data in healthcare. Stakeholders, including healthcare providers, data scientists, and policymakers, must collaborate to develop robust methodologies to mitigate these limitations effectively. Only then can synthetic data fully realize its potential to transform healthcare analytics.
Future Directions
Standardized Validation Protocols
For synthetic data to gain more widespread acceptance and utility, there needs to be a standardized set of protocols for its validation. Efforts are being made in this direction, and the sooner the industry can agree on these standards, the faster synthetic data can be employed for various use cases.
Machine Learning and AI
As machine learning and artificial intelligence technologies continue to advance, the role of synthetic health data for analytics is likely to expand. Advanced algorithms could be trained on synthetic data to develop diagnostic tools, predictive models, and various other applications that can significantly enhance healthcare outcomes.
Conclusion
Synthetic data in healthcare is a growing field with enormous potential. Its ability to balance data utility against privacy makes it an especially attractive option for researchers, healthcare providers, and policymakers. The integration of text mining in healthcare with synthetic data can further enhance predictive analytics and patient care insights. Though challenges remain, particularly around data leakage and validation, ongoing research and technological advancements promise to mitigate these issues.
Synthetic healthcare data presents a fascinating opportunity to revolutionize healthcare analytics, policy planning, and clinical research. As we look toward the future, it is clear that synthetic data will play an increasingly vital role in shaping the landscape of healthcare analytics. By understanding its potential and limitations, the healthcare industry can better harness this tool, optimizing outcomes while ensuring data privacy and integrity.
With initiatives already in place to validate and standardize synthetic data, its future seems promising. As healthcare data grows in volume and complexity, synthetic data stands out as an invaluable resource that could redefine the paradigms of data management and analytics in healthcare. Partnering with trusted providers of healthcare data analytics services allows organizations to fully leverage synthetic datasets for research, predictive modeling, and clinical decision-making while ensuring data privacy and compliance.