Healthcare organizations in the U.S. are investing substantial resources in digital tools, data enablement platforms, and analytics. Deloitte’s 2025 healthcare executive outlook indicates that leaders anticipate digital transformation to significantly impact the operation of health systems over the next few years. The healthcare analytics market is already valued in the tens of billions of dollars, with strong growth anticipated ahead. At the same time, another survey claims that automation frequently results in additional clicks and documentation, with burnout remaining a continual problem.
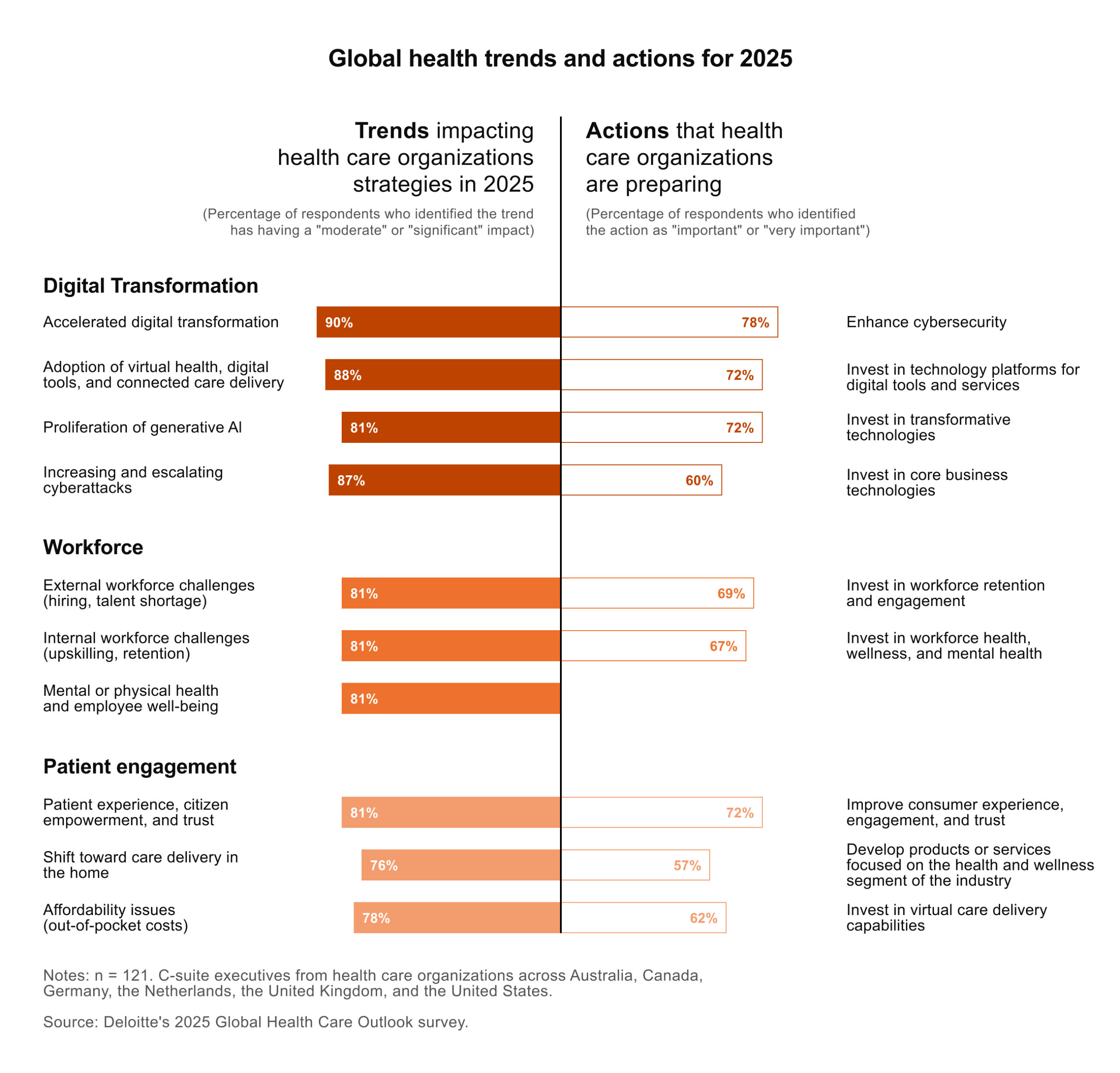
On paper, that is progress. In practice, the picture is less organized. According to a recent survey, U.S. health institutions are investing billions of dollars in business technology, yet many still struggle to articulate the value they derive from it. For data, analytics, and information leaders, the question is how to make data investments result in smarter decisions, safer operations, and a truly data-informed culture. This is where a defined data enablement plan comes in.
This article presents a practical perspective on what data enablement entails in healthcare and outlines the key components of a modern data enablement framework. It also demonstrates how Kodjin, as healthcare analytics software, can transform raw records into business-, analytics-, and AI-ready assets that clinicians, payers, and regulators can effectively utilize.
Highlights:
- U.S. healthcare is investing billions in digital tools and analytics, yet many leaders still struggle to connect that spend to patient outcomes, staff experience, or strategy.
- Data enablement shifts the focus from “more data” to governed, self-service access that enables clinicians, managers, and payers to work from the same live picture, rather than fighting over spreadsheets.
- A mature data enablement framework ties together integration, data quality, usability, and literacy, providing organizations with a repeatable approach to transform new questions into reliable, actionable data products.
What Is Data Enablement?
A practical data enablement definition in healthcare is ensuring that people can quickly access the data they need, trust it, and use it in real-world decisions without needing to consult an engineer every time. Instead of being “one more database,” it acts as a layer between core systems and frontline tools, turning raw records into clear concepts for clinicians, case managers, and finance teams. For example, a cardiac care coordinator might review patients discharged after a heart attack in the past seven days with elevated troponin who still have no documented follow-up plan.
Within this model, your enablement data layer sits between transactional systems and frontline products. It translates data into business concepts that clinicians, case managers, and finance teams understand. Instead of pushing requests into a central backlog, they have governed access to reusable datasets, metrics, and semantic definitions that support daily work and long-term management.
The Role of Data Enablement in Healthcare Transformation
Enabling better population health and patient outcomes
Population health programs and value contracts depend on complete longitudinal views of patients and cohorts. Without enablement, critical data about conditions, procedures, utilization, and Social Determinants of Health (SDOH) sit in separate environments.
With a good data enablement strategy, you bring electronic health records (EHRs), claims, registries, wearable data, and social factors into one stable view of patients and cohorts. Care teams can see high-risk patients earlier, understand where pathways break, and focus interventions where they are most needed. Based on our experience, the first real gains often come from answering a few very specific questions, rather than trying to rebuild everything at once.
Supporting value-based care through integrated data
Value-based care requires more than end-of-quarter reports to payers. It needs near real-time visibility into measures, attribution, and total cost of care across networks.
Without data-driven data enablement, the process is slow and messy. At the end of each quarter, the payer sends a claims extract, the provider pulls its own EHR and billing data, and both sides rebuild the same measures in different tools. Teams spend weeks comparing spreadsheets, arguing about denominators, and trying to explain why care gap counts do not match. By the time they agree on the numbers, the chance to change outcomes for that period is gone.
With a data enablement approach, standards like Fast Healthcare Interoperability Resources (FHIR) and modern Application Programming Interfaces (APIs) feed a shared, governed data layer. Measures, attribution rules, and cohort definitions are all stored in one place, allowing both payer and provider to work from the same data set. Care managers can see up-to-date gaps in care lists each morning, while contract teams track performance against value-based contracts during the quarter.
Empowering clinicians and analysts with self-service data access
For many health systems, the real bottleneck is people. Clinicians, quality leads, and finance teams often wait weeks for a minor dashboard change because every question is routed through a single analytics backlog.
Data enablement addresses this by pairing governed self-service with business-friendly models. Instead of writing SQL, users work with clinical concepts, such as patient, episode, treatment phase, and denial reason, inside governed interfaces. They can explore analytics, test ideas, and get answers quickly, while you keep control.
Key Components of Data Enablement
1. Data integration and interoperability
First, you need robust integration and normalization. Healthcare data arrives in every possible format: HL7 v2, proprietary schemas, flat files, and emerging FHIR feeds.
Kodjin’s architecture enables these raw inputs to be transformed into standards-based, FHIR-native structures with terminology mappings and historization. This becomes the foundation for enablement data reporting, AI, quality programs, and external exchange.
2. Data quality
Second, data must be consistent and trustworthy. Many organizations have governance policies in place, but they are often difficult to enforce.
In Kodjin, quality and governance are built into the pipeline. Validation rules run as data arrives. Coding and terminology are checked against shared dictionaries. Lineage indicates the origin of each number. That helps auditors, regulators, and clinical teams understand and trust what they see.
3. Data accessibility and usability
Third, people who make decisions must actually use the data. Giving them access to more Business Intelligence (BI) tools is not enough. They need models that speak their language.
Kodjin was designed as an analytics enablement layer on top of standards-based storage. It reshapes FHIR records into concepts like “episode of care” and “treatment plan” and exposes them via semantic models and a conversational interface.
4. Data literacy and collaboration
People need to feel comfortable using data. In practice, Kodjin works best when it is paired with light training and simple playbooks: short sessions, concrete examples, and regular reviews of shared dashboards. Over time, this helps teams naturally start with, “What does the data show?” when making decisions.
Data Enablement vs. Data Governance in Healthcare
Data governance and data enablement are often lumped together, but they address different aspects of the same problem. Governance is the rulebook. It defines who owns which data, what “good quality” means, how long you keep records, and how privacy and security are protected.
Data enablement is about what happens next. It examines whether people can effectively utilize the governed data in real-life situations. Enablement is what transforms governed data into something that naturally integrates into daily work.
When things go well, governance and enablement support each other. Policies appear as access rules, validation checks, and shared definitions within your data platform. Additionally, enablement provides semantic models, self-service tools, and workflow integrations that already adhere to these rules.
The table below summarizes the main differences:
| Aspect | Data governance | Data enablement |
| Main question | “Are we allowed to use this data, and under what conditions?” | “Can people actually use this data in their day-to-day work?” |
| Primary focus | Rules, ownership, quality standards, privacy, and security | Access, usability, workflows, and turning data into decisions |
| Typical owners | Compliance, legal, security, data owners | Clinical, operations, finance, and analytics teams |
| Main outputs | Policies, controls, data standards, catalogs | Data products, dashboards, semantic models, self-service tools |
| Risk if missing | Regulatory breaches, conflicting sources of truth, and data misuse | Low adoption, manual reporting, slow or inconsistent decisions |
Benefits of Data Enablement for Healthcare Organizations
Below are some of the most common areas where providers and payers see measurable impact once their data is truly enabled:
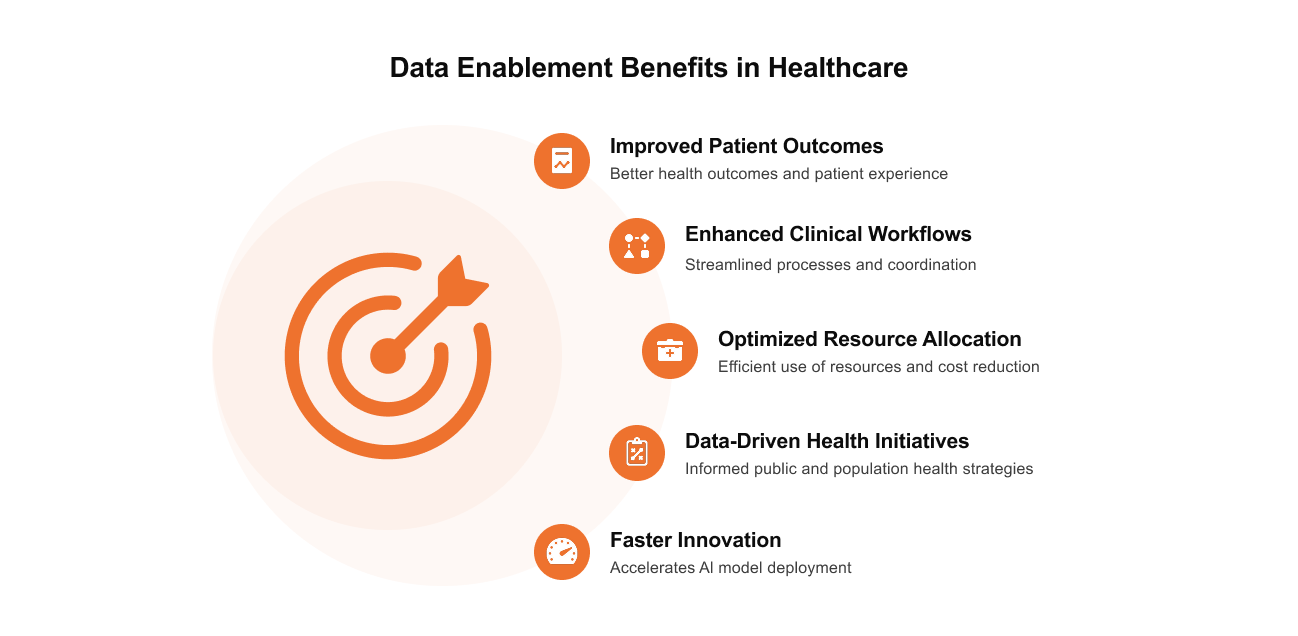
Improved patient outcomes and experience
When clinical and administrative data align around patients and cohorts, care teams can see the whole picture. They can identify screening gaps, monitor adherence, and compare results by population, site, or provider group. Kodjin’s semantic layer and cohort logic make this type of longitudinal perspective routine, enabling teams to adapt outreach, refine treatment pathways, and monitor how changes impact patient and customer experiences.
Enhanced clinical workflows and coordination
When data is truly enabled, it appears right where clinicians already work. A nurse manager can monitor patient flow and boarding as it occurs, and a care coordinator instantly identifies which patients have missed follow-up labs. Kodjin’s visualizations and conversational analytics layer seamlessly integrate with existing workflows, making bottlenecks easier to identify.
Optimized resource allocation and reduced costs
When your organization’s data is ready to use, you can match resources to real demand. You can identify which procedures and patient groups account for the majority of the cost, where the length of stay is increasing, and how readmission patterns vary across sites. Analytics like this are proven to help reduce unnecessary length of stay and readmission rates, lowering costs and improving patient health. Kodjin makes it easy for finance and service‑line leaders to drill into those trends by payer, facility, or diagnosis, which supports smarter utilization, more informed negotiations with payers, and healthier margins.
Faster innovation and AI model deployment
Many teams have promising AI models that never move beyond the pilot stage, usually because data access, quality, and monitoring are not yet ready. A strong enablement layer removes those blockers. Kodjin offers curated, well-documented data products and an AI-friendly semantic layer, making it much easier to train, deploy, and monitor models in real-world workflows.
Common Challenges in Healthcare Data Enablement
Even with the right vision, data enablement runs into very familiar obstacles. Most come from long-standing technical debt, fragmented ownership, and the realities of clinical work. Here are some of the most common issues and how Kodjin helps address them.
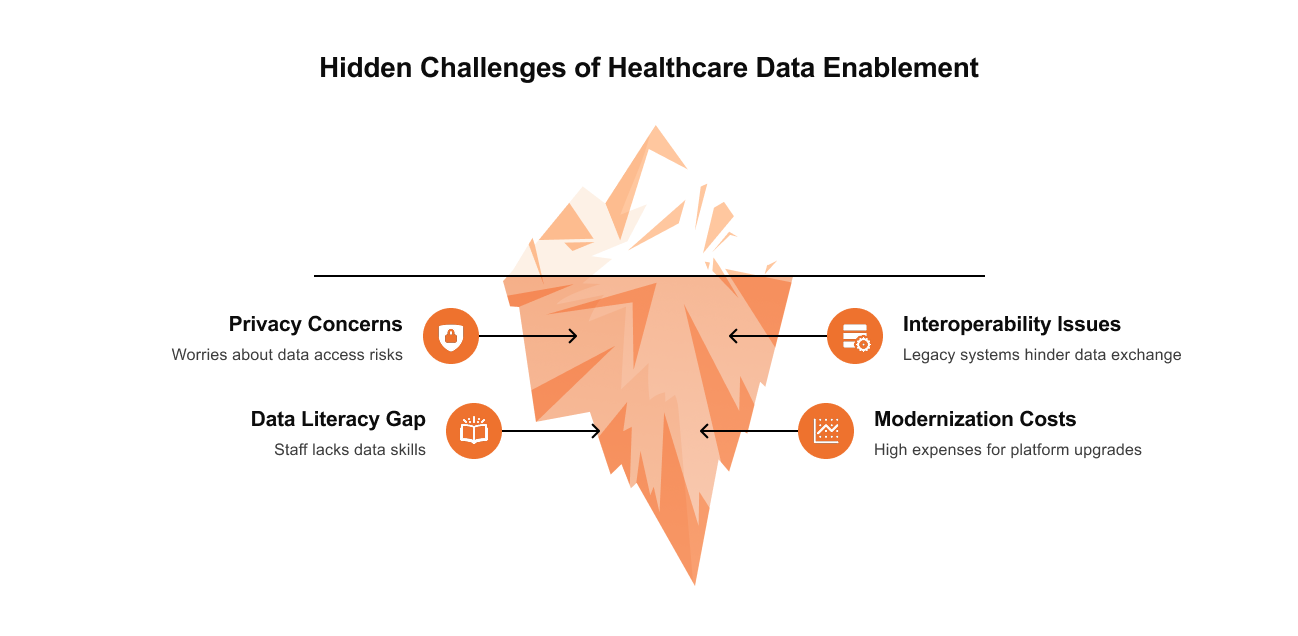
Data silos across hospitals, payers, and EHR systems
Large systems usually run several EHRs, billing platforms, and care management tools. Payers keep their own view of members and claims. Without a shared layer on top, each group ends up with its own “truth,” and simple questions turn into long rounds of reconciliation.
Kodjin pulls data from these different systems and brings it into a shared semantic model. Local specifics are preserved where they matter, but everyone works from a common backbone. That makes real collaboration between hospitals, payers, and partners possible.
Privacy and regulatory compliance
Health data is sensitive and highly regulated. Leaders worry, with good reason, that wider access could create new risks or draw unwanted attention from regulators. As a result, many teams err on the side of locking data down.
Kodjin’s architecture keeps Protected Health Information (PHI) inside a controlled, standards-based environment and shows each user only what their role requires. Governance policies, detailed audit trails, and a strong security posture are required to stay on the right side of the law. This helps support compliance with the Health Insurance Portability and Accountability Act (HIPAA), rules from the Office of the National Coordinator for Health Information Technology (ONC), and, where applicable, the General Data Protection Regulation (GDPR), while still leaving room for meaningful use of the data.
Lack of interoperability between legacy systems
Many organizations still depend on legacy HL7 feeds, custom interfaces, and point-to-point links. Every new use case needs another fragile connection, and small changes can break a whole chain. That slows down new projects and raises integration costs.
Kodjin uses FHIR, terminology services, and flexible pipelines to turn these legacy structures into standardized resources and centralized mappings. Once this backbone is in place, you can support many new use cases on the same fabric.
Limited data literacy among healthcare staff
Clinicians and operational leaders already juggle full schedules. Few have the time or desire to learn complex data tools. If every basic question becomes an analytics ticket, data enablement stays stuck in theory.
Kodjin lowers this barrier with concept-based semantic models, guided interfaces, and conversational analytics. Short, focused training sessions help teams learn just enough to ask better questions and link data to daily work.
High cost and complexity of modernization
Many data platforms present a tough choice. Developer-first stacks are powerful but hard for business users. Business-focused tools feel simple at first, but can be rigid and stiff to extend. In both cases, full rollout can take years before anyone sees clear value.
Kodjin takes a more gradual and practical route. It includes key modules such as ingestion, FHIR storage, terminology, semantic framework, and analytics, but still adapts to your environment.
How to Build a Data Enablement Framework
A data enablement framework is more than an architecture diagram. It ties together why you need the data, who will use it, and how it is used to inform real decisions. To make it work, follow these practical steps:
- Start with the data product and outcomes. Define the “data product” you want to build and the question it should answer, whether it’s managing chronic disease cohorts, reducing denials, or tracking value‑based care performance. Knowing which outcomes and metrics matter will keep you from collecting data “just in case.”
- Clarify who will use it. Identify the roles that will rely on this product, perhaps a chief medical information officer, a care manager, a quality lead, a service‑line director, or a revenue‑cycle analyst. Understanding their decisions will shape how detailed your models need to be and what level of self‑service access makes sense.
- Map your data sources, formats, and gaps. Once you know your purpose and users, list your sources. These might include EHRs, claims, registries, devices, and social-determinant feeds. Note their origin, the formats in which they arrive (HL7 v2, FHIR, CSV, proprietary), and how frequently they are updated. Identify the missing fields or populations that could limit your product.
- Set quality rules, metadata, and observability. Decide what “good enough” data looks like by setting requirements for completeness, accuracy, timeliness, and coding quality. Create a lightweight catalogue entry that describes the key fields, definitions, owners, and relationships of the data products. Add observability and lineage so you can see where data originates and how it changes when an issue occurs.
- Design the data lifecycle. Treat the data product like a living thing. Define how you acquire data (who sends it and when), how you ingest it (how it lands in your infrastructure), how you curate it (transformations, validations, and enrichments), and how long you keep each layer under your regulatory constraints. Documenting this makes it easier to onboard new sources, satisfy auditors, and prevent uncontrolled copies.
- Choose and configure the right tools. Only after you understand your data’s lifecycle should you choose technology. Decide what you need at each stage: FHIR APIs, integration services, storage (data lakes, cloud, or clinical warehouses), cataloguing, lineage, access control, and analytics interfaces. A platform like Kodjin can consolidate ingestion, FHIR storage, terminology, lineage, and semantics, so configuration replaces building everything from scratch.
- Build, deploy, and iterate. Finally, build your pipelines, publish the data product, and let real users try it. Encourage cross‑functional teams (clinical, operational, financial, analytic) to co‑own it, monitor its use, and provide feedback. Measure adoption and impact, then refine your models, quality rules, and interfaces. A strong framework provides a repeatable way to transform new questions into reliable and trusted data products.
Why Choose Kodjin for Healthcare Data Enablement
Kodjin is built for mid-sized and large healthcare organizations that want serious control over their data without building everything from scratch. It acts as a healthcare-specific data fabric and analytics layer that can be tailored to your infrastructure, contracts, and use cases.
Key strengths include:
- Semantic FHIR analytics. Kodjin turns nested FHIR records into clear clinical concepts such as patient, episode of care, treatment phase, and pathway. It reshapes fragmented records into longitudinal views of care, cost, and outcomes, optimized to query millions of resources with stable performance.
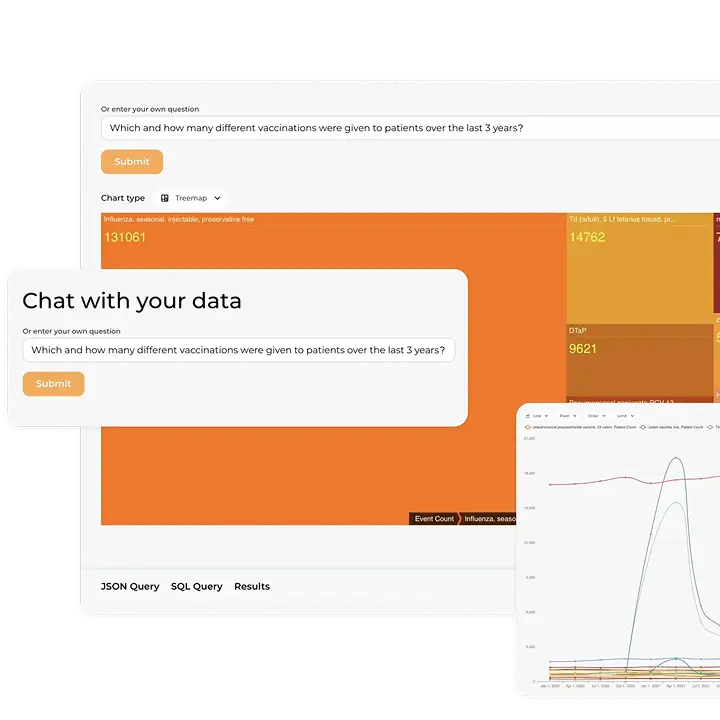
- AI-assisted, conversational access to insights. Users can “chat with their data” in plain language. The built-in AI assistant converts questions into the right queries, so clinicians, managers, and finance teams get timely answers without waiting on SQL specialists or overworked analytics departments.
- End-to-end data enablement platform integration. Kodjin Analytics sits on top of a full FHIR data platform that includes Extract, Load, Transform (ELT) pipelines, terminology services, and a high-performance FHIR server. Data can be ingested from diverse sources, validated, standardized, and historicized before it reaches the analytics layer, which ensures your metrics are consistent and audit-ready.
- Ready-to-use. Out of the box, you get user interfaces, reports, and visualizations for clinical, operational, revenue cycle, and population health analytics. At the same time, an API-first “headless BI” approach lets you connect tools like Power BI or Tableau or embed analytics directly into your apps.
In practice, organizations get the most value when they treat Kodjin as the backbone of their data enablement efforts. It becomes a shared environment where clinical, financial, and operational teams view the exact numbers, ask better questions, and transition from one-off analyses to a steady rhythm of informed decisions.
Conclusion
Most healthcare organizations have already made substantial investments in digital tools and data platforms. The challenge now is turning that investment into better decisions, smoother operations, and less burnout. Data enablement provides the missing link: it brings ingestion, standards, governance, and self‑service into a single operating model, and it reminds us that habits and ownership matter as much as architecture. When these pieces come together, clinicians see the full story of a patient, managers see the exact numbers, and executives can ask harder questions without slowing down the system. Kodjin gives data enablement a concrete backbone by turning fragmented records into FHIR‑based, semantic, AI‑ready assets and making them accessible through conversational analytics.
Curious how Kodjin could work with your current EHRs, claims data, and analytics stack?
Book a short demo with our team and walk through a scenario based on your real use cases.
FAQs
What’s the difference between data enablement and interoperability?
Interoperability focuses on how systems exchange data, including formats, APIs, and messaging standards such as FHIR or HL7 v2. It answers, “Can these applications talk to each other?” Data enablement goes further. It asks, “Can our people actually use that data to make better decisions?” It includes integration, semantics, quality, governance, self-service, and culture. Interoperability is an essential part of the picture, but enablement is what turns shared data into real clinical and financial value.
How does data enablement improve patient outcomes?
Enabled data allows care teams to see trends and gaps across the entire patient journey. They can identify high-risk cohorts earlier, monitor adherence, and see how changes in care pathways affect outcomes.
What are the first steps toward healthcare data enablement?
Most organizations begin by clarifying their goals: which decisions, programs, or contracts they aim to improve over the next 12–18 months. From there, leaders identify priority data domains, often admissions, chronic disease, or revenue cycle, and map current flows and pain points.
How can data enablement support AI adoption in healthcare?
AI models require consistent, well-governed data and clear feedback loops. Without that foundation, pilots may look promising but stall before reaching production.
A strong enablement layer provides curated datasets, semantic definitions, and monitoring infrastructure that data science teams can trust. Kodjin’s architecture and AI-ready analytics interface were designed with this in mind, enabling organizations to transition from experiments to reliable AI services seamlessly embedded in care and payment workflows.
What role does FHIR play in healthcare data enablement?
FHIR has become a key standard for representing and exchanging clinical data in U.S. initiatives, including ONC’s API rules. It provides a standardized structure that facilitates the integration of data from various vendors and care settings. Kodjin builds on FHIR by adding historization, terminology services, and a semantic analytics layer. That turns FHIR from a transport standard into a durable backbone for enablement, supporting everything from reporting and quality to AI-ready data products and cross-organizational innovation.